tl;dr:
Ok-wrapping as needed in today s Rust is a significant distraction, because there are multiple ways to do it. They are all slightly awkward in different ways, so are least-bad in different situations. You must choose a way for every fallible function, and sometimes change a function from one pattern to another.
Rust really needs
#[throws] as a first-class language feature. Code using
#[throws] is simpler and clearer.
Please try out withoutboats s
fehler. I think you will like it.
Contents
A recent personal experience in coding style
Ever since I read withoutboats s
2020 article about
fehler, I have been using it in most of my personal projects.
For
Reasons I recently had a go at eliminating the dependency on
fehler from
Hippotat. So, I made a branch, deleted the dependency and imports, and started on the whack-a-mole with the compiler errors.
After about a half hour of this, I was starting to feel queasy.
After an hour I had decided that basically everything I was doing was making the code worse. And, bizarrely, I kept having to make
individual decisons about what idiom to use in each place. I couldn t face it any more.
After sleeping on the question I decided that Hippotat would be in Debian
with fehler, or not at all. Happily the Debian Rust Team generously helped me out, so the answer is that
fehler is now in Debian, so it s fine.
For me this experience, of trying to convert Rust-with-
#[throws] to Rust-without-
#[throws] brought the
Ok wrapping problem into sharp focus.
What is
Ok wrapping? Intro to Rust error handling
(You can skip this section if you re already a seasoned Rust programer.)
In Rust, fallibility is represented by functions that return
Result<SuccessValue, Error>: this is a generic type, representing either whatever
SuccessValue is (in the
Ok variant of the data-bearing enum) or some
Error (in the
Err variant). For example,
std::fs::read_to_string, which takes a filename and returns the contents of the named file, returns
Result<String, std::io::Error>.
This is a nice and typesafe formulation of, and generalisation of, the traditional C practice, where a function indicates in its return value whether it succeeded, and errors are indicated with an error code.
Result is part of the standard library and there are convenient facilities for checking for errors, extracting successful results, and so on. In particular, Rust has the postfix
? operator, which, when applied to a
Result, does one of two things: if the
Result was
Ok, it yields the inner successful value; if the
Result was
Err, it returns early from the current function, returning an
Err in turn to the caller.
This means you can write things like this:
let input_data = std::fs::read_to_string(input_file)?;
and the error handling is pretty automatic. You get a compiler warning, or a type error, if you forget the
?, so you can t accidentally ignore errors.
But, there is a downside. When you are returning a successful outcome from your function, you must convert it into a
Result. After all, your fallible function has return type
Result<SuccessValue, Error>, which is a different type to
SuccessValue. So, for example, inside
std::fs::read_to_string, we see this:
let mut string = String::new();
file.read_to_string(&mut string)?;
Ok(string)
string has type
String;
fs::read_to_string must return
Result<String, ..>, so at the end of the function we must return
Ok(string). This applies to
return statements, too: if you want an early successful return from a fallible function, you must write
return Ok(whatever).
This is particularly annoying for functions that don t actually return a nontrivial value. Normally, when you write a function that doesn t return a value you don t write the return type. The compiler interprets this as syntactic sugar for
-> (), ie, that the function returns
(), the empty tuple, used in Rust as a dummy value in these kind of situations. A block (
... ) whose last statement ends in a
; has type
(). So, when you fall off the end of a function, the return value is
(), without you having to write it. So you simply leave out the stuff in your program about the return value, and your function doesn t have one (i.e. it returns
()).
But, a function which either fails with an error, or completes successfuly without returning anything, has return type
Result<(), Error>. At the end of such a function, you must explicitly provide the success value. After all, if you just fall off the end of a block, it means the block has value
(), which is not of type
Result<(), Error>. So the fallible function must end with
Ok(()), as we see in
the example for std::fs::read_to_string.
A minor inconvenience, or a significant distraction?
I think the need for
Ok-wrapping on all success paths from fallible functions is generally regarded as just a minor inconvenience. Certainly the experienced Rust programmer gets very used to it. However, while trying to remove
fehler s
#[throws] from Hippotat, I noticed something that is evident in codebases using vanilla Rust (without
fehler) but which goes un-remarked.
There are multiple ways to write the
Ok-wrapping, and the different ways are appropriate in different situations.
See the following examples, all taken from a
real codebase. (And it s not just me: I do all of these in different places, - when I don t have
fehler available - but all these examples are from code written by others.)
Idioms for
Ok-wrapping - a bestiary
Wrap just a returned variable binding
If you have the return value in a variable, you can write
Ok(reval) at the end of the function, instead of
retval.
pub fn take_until(&mut self, term: u8) -> Result<&'a [u8]>
// several lines of code
Ok(result)
If the returned value is not already bound to variable, making a function fallible might mean choosing to bind it to a variable.
Wrap a nontrivial return expression
Even if it s not just a variable, you can wrap the expression which computes the returned value. This is often done if the returned value is a struct literal:
fn take_from(r: &mut Reader<'_>) -> Result<Self>
// several lines of code
Ok(AuthChallenge challenge, methods )
Introduce
Ok(()) at the end
For functions returning
Result<()>, you can write
Ok(()).
This is usual, but
not ubiquitous, since sometimes you can omit it.
Wrap the whole body
If you don t have the return value in a variable, you can wrap the whole body of the function in
Ok( ). Whether this is a good idea depends on how big and complex the body is.
fn from_str(s: &str) -> std::result::Result<Self, Self::Err>
Ok(match s
"Authority" => RelayFlags::AUTHORITY,
// many other branches
_ => RelayFlags::empty(),
)
Omit the wrap when calling fallible sub-functions
If your function wraps another function call of the same return and error type, you don t need to write the
Ok at all. Instead, you can simply call the function and not apply
?.
You can do this even if your function selects between a number of different sub-functions to call:
fn fmt(&self, f: &mut std::fmt::Formatter<'_>) -> std::fmt::Result
if flags::unsafe_logging_enabled()
std::fmt::Display::fmt(&self.0, f)
else
self.0.display_redacted(f)
But this doesn t work if the returned error type isn t the same, but needs the autoconversion implied by the
? operator.
Convert a fallible sub-function error with
Ok( ... ?)
If the final thing a function does is chain to another fallible function, but with a different error type, the error must be converted somehow. This can be done with
?.
fn try_from(v: i32) -> Result<Self, Error>
Ok(Percentage::new(v.try_into()?))
Convert a fallible sub-function error with
.map_err
Or, rarely, people solve the same problem by converting explicitly with
.map_err:
pub fn create_unbootstrapped(self) -> Result<TorClient<R>>
// several lines of code
TorClient::create_inner(
// several parameters
)
.map_err(ErrorDetail::into)
What is to be done, then?
The
fehler library is in excellent taste and has the answer. With
fehler:
- Whether a function is fallible, and what it s error type is, is specified in one place. It is not entangled with the main return value type, nor with the success return paths.
- So the success paths out of a function are not specially marked with error handling boilerplate. The end of function return value, and the expression after
return, are automatically wrapped up in Ok. So the body of a fallible function is just like the body of an infallible one, except for places where error handling is actually involved.
- Error returns occur through
? error chaining, and with a new explicit syntax for error return.
- We usually talk about the error we are possibly returning, and avoid talking about
Result unless we need to.
fehler provides:
- An attribute macro
#[throws(ErrorType)] to make a function fallible in this way.
- A macro
throws!(error) for explicitly failing.
This is precisely correct. It is very ergonomic.
Consequences include:
- One does not need to decide where to put the
Ok-wrapping, since it s automatic rather than explicitly written out.
- Specifically, what idiom to adopt in the body (for example
write!(...)?; vs write!(...) in a formatter) does not depend on whether the error needs converting, how complex the body is, and whether the final expression in the function is itself fallible.
- Making an infallible function fallible involves only adding
#[throws] to its definition, and ? to its call sites. One does not need to edit the body, or the return type.
- Changing the error returned by a function to a suitably compatible different error type does not involve changing the function body.
- There is no need for a local
Result alias shadowing std::result::Result, which means that when one needs to speak of Result explciitly, the code is clearer.
Limitations of fehler
But, fehler is a Rust procedural macro, so it cannot get everything right. Sadly there are some wrinkles.
- You can t write
#[throws] on a closure.
- Sometimes you can get quite poor error messages if you have a sufficiently broken function body.
- Code inside a macro call isn t properly visible to
fehler so sometimes return statements inside macro calls are untreated. This will lead to a type error, so isn t a correctness hazard, but it can be nuisance if you like other syntax extensions eg if_chain.
#[must_use] #[throws(Error)] fn obtain() -> Thing; ought to mean that Thing must be used, not the Result<Thing, Error>.
But, Rust-with-
#[throws] is so much nicer a language than Rust-with-mandatory-
Ok-wrapping, that these are minor inconveniences.
Please can we have
#[throws] in the Rust language
This ought to be part of the language, not a macro library. In the compiler, it would be possible to get the all the corner cases right. It would make the feature available to everyone, and it would quickly become idiomatic Rust throughout the community.
It is evident from reading writings from the time, particularly those from withoutboats, that there were significant objections to automatic
Ok-wrapping. It seems to have become quite political, and some folks burned out on the topic.
Perhaps, now, a couple of years later, we can revisit this area and solve this problem in the language itself ?
Explicitness
An argument I have seen made against automatic
Ok-wrapping, and, in general, against any kind of useful language affordance, is that it makes things less explicit.
But this argument is fundamentally wrong for
Ok-wrapping. Explicitness is not an unalloyed good. We humans have only limited attention. We need to focus that attention where it is actually needed. So explicitness is good in situtions where what is going on is unusual; or would otherwise be hard to read; or is tricky or error-prone. Generally: explicitness is good for things where we need to direct humans attention.
But
Ok-wrapping is ubiquitous in fallible Rust code. The compiler mechanisms and type systems almost completely defend against mistakes. All but the most novice programmer knows what s going on, and the very novice programmer doesn t need to. Rust s error handling arrangments are designed specifically so that we can avoid worrying about fallibility unless necessary except for the
Ok-wrapping. Explicitness about
Ok-wrapping directs our attention away from whatever other things the code is doing: it is a distraction.
So, explicitness about
Ok-wrapping is a
bad thing.
Appendix - examples showning code with
Ok wrapping is worse than code using
#[throws]
Observe these diffs, from my abandoned attempt to remove the
fehler dependency from Hippotat.
I have a type alias
AE for the usual error type (
AE stands for
anyhow::Error). In the non-
#[throws] code, I end up with a type alias
AR<T> for
Result<T, AE>, which I think is more opaque but at least that avoids typing out
-> Result< , AE> a thousand times. Some people like to have a local
Result alias, but that means that the standard
Result has to be referred to as
StdResult or
std::result::Result.
With fehler and #[throws]
|
Vanilla Rust, Result<>, mandatory Ok-wrapping
|
|
|
Return value clearer, error return less wordy:
|
impl Parseable for Secret
|
impl Parseable for Secret
|
#[throws(AE)]
|
|
fn parse(s: Option<&str>) -> Self
|
fn parse(s: Option<&str>) -> AR<Self>
|
let s = s.value()?;
|
let s = s.value()?;
|
if s.is_empty() throw!(anyhow!( secret value cannot be empty ))
|
if s.is_empty() return Err(anyhow!( secret value cannot be empty ))
|
Secret(s.into())
|
Ok(Secret(s.into()))
|
|
|
|
|
No need to wrap whole match statement in Ok( ):
|
#[throws(AE)]
|
|
pub fn client<T>(&self, key: & static str, skl: SKL) -> T
|
pub fn client<T>(&self, key: & static str, skl: SKL) -> AR<T>
|
where T: Parseable + Default
|
where T: Parseable + Default
|
match self.end
|
Ok(match self.end
|
LinkEnd::Client => self.ordinary(key, skl)?,
|
LinkEnd::Client => self.ordinary(key, skl)?,
|
LinkEnd::Server => default(),
|
LinkEnd::Server => default(),
|
|
)
|
|
|
Return value and Ok(()) entirely replaced by #[throws]:
|
impl Display for Loc
|
impl Display for Loc
|
#[throws(fmt::Error)]
|
|
fn fmt(&self, f: &mut fmt::Formatter)
|
fn fmt(&self, f: &mut fmt::Formatter) -> fmt::Result
|
write!(f, :? : , &self.file, self.lno)?;
|
write!(f, :? : , &self.file, self.lno)?;
|
if let Some(s) = &self.section
|
if let Some(s) = &self.section
|
write!(f, )?;
|
write!(f, )?;
|
|
|
|
|
|
Ok(())
|
|
|
Call to write! now looks the same as in more complex case shown above:
|
impl Debug for Secret
|
impl Debug for Secret
|
#[throws(fmt::Error)]
|
|
fn fmt(&self, f: &mut fmt::Formatter)
|
fn fmt(&self, f: &mut fmt::Formatter)-> fmt::Result
|
write!(f, "Secret(***)")?;
|
write!(f, "Secret(***)")
|
|
|
|
|
Much tiresome return Ok() noise removed:
|
impl FromStr for SectionName
|
impl FromStr for SectionName
|
type Err = AE;
|
type Err = AE;
|
#[throws(AE)]
|
|
fn from_str(s: &str) -> Self
|
fn from_str(s: &str) ->AR< Self>
|
match s
|
match s
|
COMMON => return SN::Common,
|
COMMON => return Ok(SN::Common),
|
LIMIT => return SN::GlobalLimit,
|
LIMIT => return Ok(SN::GlobalLimit),
|
_ =>
|
_ =>
|
;
|
;
|
if let Ok(n@ ServerName(_)) = s.parse() return SN::Server(n)
|
if let Ok(n@ ServerName(_)) = s.parse() return Ok(SN::Server(n))
|
if let Ok(n@ ClientName(_)) = s.parse() return SN::Client(n)
|
if let Ok(n@ ClientName(_)) = s.parse() return Ok(SN::Client(n))
|
|
|
if client == LIMIT return SN::ServerLimit(server)
|
if client == LIMIT return Ok(SN::ServerLimit(server))
|
let client = client.parse().context( client name in link section name )?;
|
let client = client.parse().context( client name in link section name )?;
|
SN::Link(LinkName server, client )
|
Ok(SN::Link(LinkName server, client ))
|
|
|
|
|
edited 2022-12-18 19:58 UTC to improve, and 2022-12-18 23:28 to fix, formatting
comments









 One of the huge benefits of
One of the huge benefits of 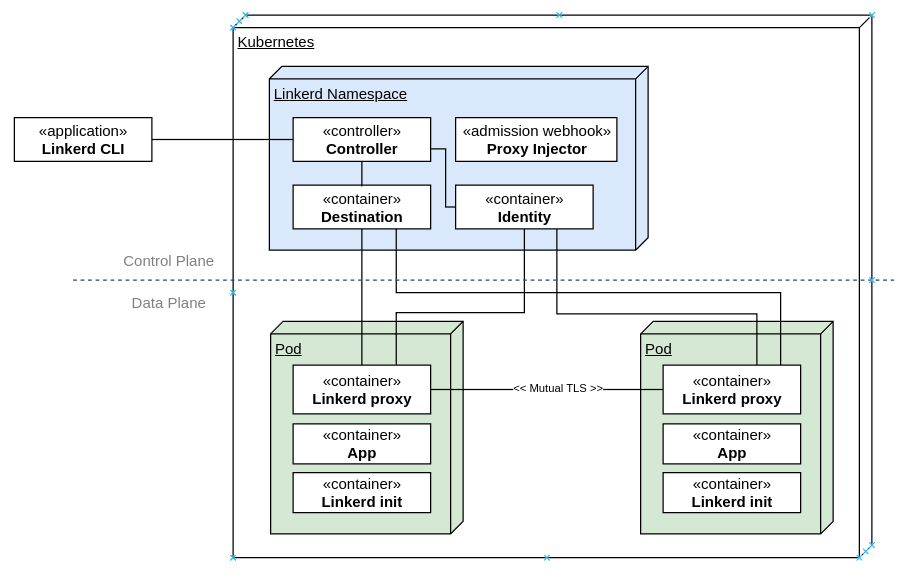
 I m trying to replace my old OpenPGP key with a new one. The old key wasn t compromised or lost or anything
bad. Is still valid, but I plan to get rid of it soon. It was created in 2013.
The new key id fingerprint is:
I m trying to replace my old OpenPGP key with a new one. The old key wasn t compromised or lost or anything
bad. Is still valid, but I plan to get rid of it soon. It was created in 2013.
The new key id fingerprint is:  I hope you had a nice Halloween!
I've collected together some songs that I've enjoyed over the last couple of
years that loosely fit a theme: ambient, instrumental, experimental, industrial,
dark, disconcerting, etc. I've prepared a Spotify playlist of most of
them, but not all. The list is inline below as well, with many (but not all)
tracks linking to Bandcamp, if I could find them there.
This is a bit late, sorry. If anyone listens to something here and has any
feedback I'd love to hear it.
(If you are reading this on an aggregation site, it's possible the embeds won't
work. If so, click through to my main site)
Spotify playlist:
I hope you had a nice Halloween!
I've collected together some songs that I've enjoyed over the last couple of
years that loosely fit a theme: ambient, instrumental, experimental, industrial,
dark, disconcerting, etc. I've prepared a Spotify playlist of most of
them, but not all. The list is inline below as well, with many (but not all)
tracks linking to Bandcamp, if I could find them there.
This is a bit late, sorry. If anyone listens to something here and has any
feedback I'd love to hear it.
(If you are reading this on an aggregation site, it's possible the embeds won't
work. If so, click through to my main site)
Spotify playlist:  Our local Debian user group gathered on Sunday October 30th to chat, work on
Debian and do other, non-Debian related hacking :) This time around, we met at
Our local Debian user group gathered on Sunday October 30th to chat, work on
Debian and do other, non-Debian related hacking :) This time around, we met at
 This was our 4th meeting this year and once again, attendance was great: 10
people showed up to work on various things.
Following our bi-monthly schedule, our next meeting should be in December, but
I'm not sure it'll happen. December can be a busy month here and I will have to
poke our mailing list to see if people have the spoons for an event.
This time around, I was able to get a rough log of the Debian work people did:
pollo:
This was our 4th meeting this year and once again, attendance was great: 10
people showed up to work on various things.
Following our bi-monthly schedule, our next meeting should be in December, but
I'm not sure it'll happen. December can be a busy month here and I will have to
poke our mailing list to see if people have the spoons for an event.
This time around, I was able to get a rough log of the Debian work people did:
pollo:

 My impression of that city from couple of visits at that point in time where they were still more tongas (horse-ridden carriages), an occasional two wheelers and not many three wheelers. Although, it was one of the more turbulent times as lot of agitation for worker rights were happening around that time and a lot of
My impression of that city from couple of visits at that point in time where they were still more tongas (horse-ridden carriages), an occasional two wheelers and not many three wheelers. Although, it was one of the more turbulent times as lot of agitation for worker rights were happening around that time and a lot of  So the last three stories I found the most intriguing.
The first one is titled Man on the Beach. Apparently, a gentleman goes to one of the beaches, a sort of lonely beach, hails a taxi and while returning suddenly dies. The Taxi driver showing good presence of mind takes it to hospital where the gentleman is declared dead on arrival. Unlike in India, he doesn t run away but goes to the cafeteria and waits there for the cops to arrive and take his statement. Now the man is in his early 40s and looks to be fit. Upon searching his pockets he is found to relatively well-off and later it turns out he owns a couple of shops. So then here are the questions ?
What was the man doing on a beach, in summer that beach is somewhat popular but other times not so much, so what was he doing there?
How did he die, was it a simple heart attack or something more? If he had been drugged or something then when and how?
These and more questions can be answered by reading the story Man on the Beach .
2. The death of a photographer Apparently, Kurt lives in a small town where almost all the residents have been served one way or the other by the town photographer. The man was polite and had worked for something like 40 odd years before he is killed/murdered. Apparently, he is murdered late at night. So here come the questions
a. The shop doesn t even stock any cameras and his cash box has cash. Further investigation reveals it is approximate to his average takeout for the day. So if it s not for cash, then what is the motive ?
b. The body was discovered by his cleaning staff who has worked for almost 20 years, 3 days a week. She has her own set of keys to come and clean the office? Did she give the keys to someone, if yes why?
c. Even after investigation, there is no scandal about the man, no other woman or any vices like gambling etc. that could rack up loans. Also, nobody seems to know him and yet take him for granted till he dies. The whole thing appears to be quite strange. Again, the answers lie in the book.
3. The Pyramid Kurt is sleeping one night when the telephone rings. The scene starts with a Piper Cherokee, a single piston aircraft flying low and dropping something somewhere or getting somebody from/on the coast of Sweden. It turns and after a while crashes. Kurt is called to investigate it. Turns out, the plane was supposed to be destroyed. On crash, both the pilot and the passenger are into pieces so only dental records can prove who they are. Same day or a day or two later, two seemingly ordinary somewhat elderly women, spinsters, by all accounts, live above the shop where they sell buttons and all kinds of sewing needs of the town. They seem middle-class. Later the charred bodies of the two sisters are found :(. So here come the questions
a.Did the plane drop something or pick something somebody up ? The Cherokee is a small plane so any plane field or something it could have landed up or if a place was somehow marked then could be dropped or picked up without actually landing.
b. The firefighter suspects arson started at multiple places with the use of petrol? The question is why would somebody wanna do that? The sisters don t seem to be wealthy and practically everybody has bought stuff from them. They weren t popular but weren t also unpopular.
c. Are the two crimes connected or unconnected? If connected, then how?
d. Most important question, why the title Pyramid is given to the story. Why does the author share the name Pyramid. Does he mean the same or the original thing? He could have named it triangle. Again, answers to all the above can be found in the book.
One thing I also became very aware of during reading the book that it is difficult to understand people s behavior and what they do. And this is without even any criminality involved in. Let s say for e.g. I die in some mysterious circumstances, the possibility of the police finding my actions in last days would be limited and this is when I have hearing loss. And this probably is more to do with how our minds are wired. And most people I know are much more privacy conscious/aware than I am.
So the last three stories I found the most intriguing.
The first one is titled Man on the Beach. Apparently, a gentleman goes to one of the beaches, a sort of lonely beach, hails a taxi and while returning suddenly dies. The Taxi driver showing good presence of mind takes it to hospital where the gentleman is declared dead on arrival. Unlike in India, he doesn t run away but goes to the cafeteria and waits there for the cops to arrive and take his statement. Now the man is in his early 40s and looks to be fit. Upon searching his pockets he is found to relatively well-off and later it turns out he owns a couple of shops. So then here are the questions ?
What was the man doing on a beach, in summer that beach is somewhat popular but other times not so much, so what was he doing there?
How did he die, was it a simple heart attack or something more? If he had been drugged or something then when and how?
These and more questions can be answered by reading the story Man on the Beach .
2. The death of a photographer Apparently, Kurt lives in a small town where almost all the residents have been served one way or the other by the town photographer. The man was polite and had worked for something like 40 odd years before he is killed/murdered. Apparently, he is murdered late at night. So here come the questions
a. The shop doesn t even stock any cameras and his cash box has cash. Further investigation reveals it is approximate to his average takeout for the day. So if it s not for cash, then what is the motive ?
b. The body was discovered by his cleaning staff who has worked for almost 20 years, 3 days a week. She has her own set of keys to come and clean the office? Did she give the keys to someone, if yes why?
c. Even after investigation, there is no scandal about the man, no other woman or any vices like gambling etc. that could rack up loans. Also, nobody seems to know him and yet take him for granted till he dies. The whole thing appears to be quite strange. Again, the answers lie in the book.
3. The Pyramid Kurt is sleeping one night when the telephone rings. The scene starts with a Piper Cherokee, a single piston aircraft flying low and dropping something somewhere or getting somebody from/on the coast of Sweden. It turns and after a while crashes. Kurt is called to investigate it. Turns out, the plane was supposed to be destroyed. On crash, both the pilot and the passenger are into pieces so only dental records can prove who they are. Same day or a day or two later, two seemingly ordinary somewhat elderly women, spinsters, by all accounts, live above the shop where they sell buttons and all kinds of sewing needs of the town. They seem middle-class. Later the charred bodies of the two sisters are found :(. So here come the questions
a.Did the plane drop something or pick something somebody up ? The Cherokee is a small plane so any plane field or something it could have landed up or if a place was somehow marked then could be dropped or picked up without actually landing.
b. The firefighter suspects arson started at multiple places with the use of petrol? The question is why would somebody wanna do that? The sisters don t seem to be wealthy and practically everybody has bought stuff from them. They weren t popular but weren t also unpopular.
c. Are the two crimes connected or unconnected? If connected, then how?
d. Most important question, why the title Pyramid is given to the story. Why does the author share the name Pyramid. Does he mean the same or the original thing? He could have named it triangle. Again, answers to all the above can be found in the book.
One thing I also became very aware of during reading the book that it is difficult to understand people s behavior and what they do. And this is without even any criminality involved in. Let s say for e.g. I die in some mysterious circumstances, the possibility of the police finding my actions in last days would be limited and this is when I have hearing loss. And this probably is more to do with how our minds are wired. And most people I know are much more privacy conscious/aware than I am.






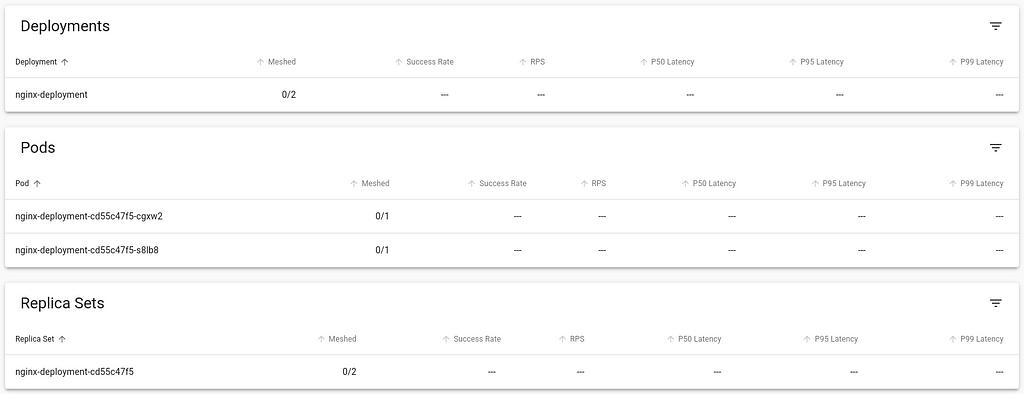
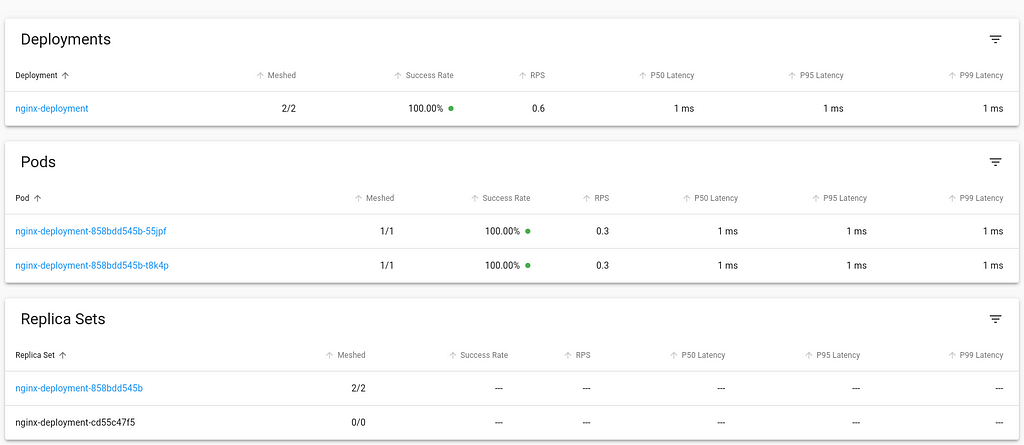
 This post describes how I ve put together a simple static content server for
kubernetes clusters using a Pod with a persistent volume and multiple
containers: an sftp server to manage contents, a web server to publish them
with optional access control and another one to run scripts which need access
to the volume filesystem.
The sftp server runs using
This post describes how I ve put together a simple static content server for
kubernetes clusters using a Pod with a persistent volume and multiple
containers: an sftp server to manage contents, a web server to publish them
with optional access control and another one to run scripts which need access
to the volume filesystem.
The sftp server runs using


{kind=link}